안전한 사용자 인증은 어떻게 만들어지는가
거의 모든 서비스는 사용자 인증 기능을 갖는다.
주의.
당연히 사람마다 역량이, 환경마다 차이가 있을 수 있음을 인지하고 있으며
이 글은 극단적인 예시를 포함하고 있다.
서비스라는 게 사용자에게 제공하는 어떤 편리한 기능적인 역할을 해야 하니 따지고 보면 당연할 수 있다.
(계산기 같은 편리함을 말하는 것이 아니라 고객이 처리할 일을 대신해주는 어떤 그런 서비스 정도를 생각했다.)
하지만 정책, 혹은 기술적인 보안 요소를 완전히 이해하지 못하고 사용자 정보를 저장하는 케이스들이 생각 외로 많이 발생한다.
우리나라의 경우 다양한 정부 관련, 혹은 연구 기관에서 안전한 보안 환경을 위한 정책적 연구를 수행하고 그에 따른 권고안을 제시한다.
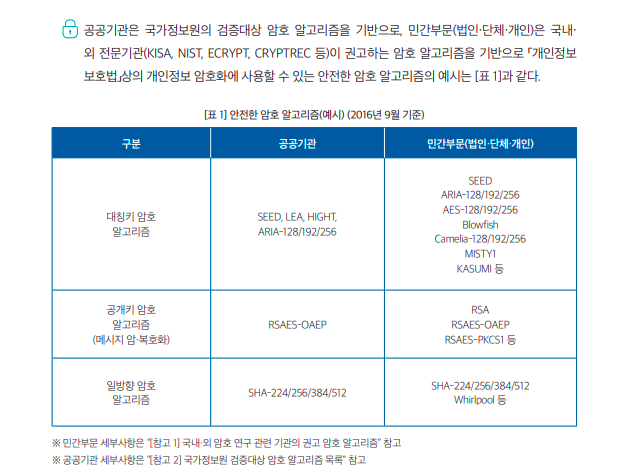

개인정보 보호 관련 정책에서 볼 수 있듯 비밀번호의 경우 단방향 암호화 알고리즘을 사용하여 복호화가 불가능하도록 조치해야 한다.
사실 여기까지는 큰 문제가 없고, 정책 또한 잘 시행되고 있는 것 같다. (이건 직접 겪어본 부분이 아니라 모르겠지만)
다만, 엔지니어들이 실제로 개발을 진행할 때에는 이 부분이 잘 전달되지 않는 것 같은데, 바로 다음으로 알아보자.
비밀번호와 같은 정보는 서버 측에서 내부적으로 처리되는 정보이기 때문에 사용자는 본인의 패스워드가 어떻게 저장되고, 처리되는지 확인할 수 없다. (그래서 정책과 법률적 제제가 필요한 부분이다.)
사용자 인증을 포함하는 서비스에서 비밀번호로 인가된 사용자 여부를 확인한다고 가정하자.
1. 비밀번호를 평문으로 저장한다. (NEVER EVER)
침해 시 평문이 그대로 유출된다.
당연히 이렇게 관리해서는 안된다.
2. 비밀번호를 안전성이 증명되지 않은 단방향 암호화로 암호화하여 저장한다. (NEVER)
단방향 암호화로 암호화하여 저장하는 경우 서버 관리자가 직접적으로 패스워드를 알 수 있는 방법은 제한되나, 해싱 알고리즘은 공개되어있기 때문에 (암호는 기본적으로 알고리즘의 공개 여부와 상관없이 암호 자체에 대한 통계적 안전성을 제공한다.) 있을 법한 평문 문자열(plain text)과 암호화된 문자열(hashed text)를 미리 확보하고 있다면 Hashed text로부터 원본 문자열을 찾아낼 수 있다.
(존재할 법한) collision 확률이 증명된 안전한지 않은 해싱 알고리즘(ex. md5)을 사용한다면 더더욱 안될 것이다.
3. 비밀번호를 안전성이 증명된 단방향 암호화로 암호화하여 저장한다. (DO NOT)
안전성이 증명된 알고리즘의 경우 byte length도 길고, (존재할 법한) collision이 없다. (어떤 문자열이던 정해진 길이로 해싱하는 단방향 암호 알고리즘의 특성상 당연히 충돌은 발생한다. 암호에서 말하는 collision이란, "존재할 법한" 수학적 충돌 가능성이다.)
하지만 2번과 같은 문제가 발생한다.
앞서 말한 2번의 경우 md5라서 단방향 암호화가 안전하지 않다는 것이 아니라 sha256을 사용할 지라도 원본 문자열과 암호화된 문자열을 확보해두는 노력의 차이는 크게 다르지 않기 때문에 해싱 알고리즘만으로는 안전을 확보할 수 없다는 의미이다.
4. 비밀번호를 안전성이 증명된 단방향 암호화와 공통 salt로 암호화하여 저장한다 (CAN BE)
2번과 3번의 경우 안전하지 않은 이유는 충분히 길지 않은 평문 문자열에 대한 평문. 암호문 셋을 미리 구성해둘 수 있기 때문이다.
따라서, 예측하기 어려울 어떤 문자열을 concat 한다면 공격자가 미리 평문. 암호문 셋을 구성할 수 없을 것이다.
특수문자를 포함한 printable ascii(화면에 출력 가능한 ASCII 문자)는 95개인데 이 범위로 8글자의 반복을 위해서는
약 6.6e+15 (95의 8승) 번의 연산을 진행해야 하는데, 사실 이 정도까지는 미리 구성해둘 수 있지만, 15글자만 넘어가도 그 수는 기하급수적으로 증가한다. 약 4.6e+29 (95의 15승) 번의 연산을 진행해야 한다.
이게 어느 정도의 수냐면
463,291,230,159,753,366,058,349,609,375
0이 29개 붙었다고 생각하면 된다.
즉, 20글자 정도의 고정된 랜덤 salt값과 사용자가 입력한 값을 concat 하여 안전한 알고리즘으로 해싱했을 때에는 사실상 공격자가 미리 테이블을 준비할 수 없게 된다.
하지만 확률적으로는 salt가 없는 것과 다르지 않다.
어차피 공통 salt를 사용하기 때문에 해시 값이 달라지는 이유는 사용자의 입력 값 때문이고, salt가 노출되게 되면, 그때부터 공격자는 salt와 concat 된 문자열 테이블을 확보하면 된다. 이때에는 salt와 보안성은 연관관계가 없어진다.
이게 엔지니어들이 salt, secret key 등을 소스코드에 직접 포함하지 말도록 조언하는 이유이고, 실제로 이런 값들을 code repository에 추가해놓는 경우엔 테이블을 미리 구성할 수 없다는 단점을 제외하면 사실상 salt는 제 기능을 하지 못한다.
실제로 개발자들이 .git과 함께 그대로 배포하는 경우 (static serving을 제공할 때) 이를 통해 공격하는 케이스도 존재한다.
5. 비밀번호를 안전성이 증명된 단방향 암호화와 dynamic salt로 암호화한다. (BEST)
사실 dynamic salt라고 하면 조금 애매한 면이 있을 것 같은데, bcrypt를 생각하면 된다.
4번의 경우 salt가 유출되었을 때의 문제(기존 사용자 인증을 위한 legacy salt와 새로 사용하는 salt를 모두 유지해야 하는 등)와 안전성의 확률적인 향상은 없다는 맹점이 존재하기 때문에 이 salt를 매 인증마다 다르게 설정하는 형태로 안전성을 유지할 수 있다.
예컨대 dynamic salt는 다음과 같은 구조를 갖는다.
random_string + HASH_ALGO(random_string + user_input)
random_string이 salt역할을 하게 되는데, HASH_ALGO 알고리즘 안에는 랜덤 스트링과 사용자 입력 값이 함께 해싱된다.
이로 인해 통계적 안전성을 확보할 수 있고, salt를 따로 관리할 필요가 없다. 애초에 데이터 안에 salt가 포함되어있고 그 값이 제각기 다르기 때문에 데이터가 한 번에 유출된 상황에서 4번 케이스의 모든 패스워드를 크랙 하는데 O(1)이라면 dynamic salt의 경우 O(n)이 소요된다.
참고로 bcrypt의 경우 버전에 따라 해싱 알고리즘을 선택할 수 있다.
- $1$: MD5-based crypt ('md5crypt')
- $2$: Blowfish-based crypt ('bcrypt')
- $sha1$: SHA-1-based crypt ('sha1crypt')
- $5$: SHA-256-based crypt ('sha256crypt')
- $6$: SHA-512-based crypt ('sha512crypt')
그리고 현대의 패스워드 보관 알고리즘의 경우 해싱 알고리즘의 iteration을 설정할 수 있게 설계되어있는데, 이 값 또한 침해 이전에 공격자는 알 수 없는 값인 데다 연산 자체를 오래 하도록 만들기 때문에 보다 높은 안전함을 제공한다.
여기까지가 비밀번호의 안전한 보관 방법과 그 이유에 대한 내용이었는데, 실제로 개발 환경을 보면 4번 수준을 유지하는 것이 생각 외로 드문 경우가 많다.
정책적으로도 약간의 문제가 있다.
(정책 자체에 문제가 있다는 것이 아니라 정확한 분석이 따르지 않는 경우가 때때로 있기 때문이다.)
예컨대, 기존 평문으로 저장하던 서비스 업체에 권고가 내려져 담당자가 md5 해시 알고리즘을 적용시켰다.
이후 재권고로 안전한 암호화 알고리즘을 사용하도록 했을 상황을 생각해보자.
단방향 알고리즘 특성상 이미 해시 값으로 업데이트해버렸다면 더 이상 그 평문을 다른 해시 알고리즘으로 암호화할 수는 없다.
더 이상 md5 해싱 알고리즘을 사용하지 않도록 조치하고, 이전 사용자가 새로 로그인한 경우 해당 사용자의 검증된 비밀번호 저장 로직으로 적용시키도록 해야 한다.
이 정도만 해도 첫 조치를 잘못 시행한 것 치고는 괜찮은 대처라고 볼 수 있다.
문제는 여기서 md5 해시 알고리즘으로 bulk update 했듯, md5 해싱된 값에 대해 sha256으로 해싱하는 형태로 진행하는 경우가 있기 때문이다. 당연하게도 md5 해싱한 값에 sha256을 덮어두는 것은 보안적으로는 미리 작성한 테이블을 사용할 수 없을 수 있지만, 수학적으로 아무 도움이 되지 않는다. 애초에 최초 해싱 값이 md5이기 때문에 16byte(128bit)로 압축되는데 그 값은 sha256으로 던 심지어 sha2048으로 다시 wrapping하건 보안적 향상은 없다.
근데 더 큰 문제는 이게 sha256으로 암호화된 형태로 보일 수 있는 것이고, 껍데기 만으로 완성된 보안 조치가 될 수 있다는 점이다.
(껍데기만 존재하는 보안은 존재 이유가 없다.)
사용자의 비밀번호를 안전하게 저장했으니, 이제 인가된 사용자만 서비스를 사용할 수 있도록 접근 제어 기능을 제공해야 한다.
이 과정은 안전한 비밀번호 저장만큼이나 중요한 주제이고, 기술적인 조치 또한 필요한 부분이다.
1. 클라이언트가 인증의 주체가 된다. (NEVER EVER)
HTTP로 치면 cookie 값에 인증 관련 정보를 넣는 것으로 예를 들 수 있다.
언제나 그렇듯 사용자의 입력 값은 보안에서 언제나 untrusted input이다.
예컨대 쿠키 정보에 유저의 PK정보를 넣어 서버 측에서 그 값을 기반으로 사용자 검증을 진행한다면, 그 값을 바꿔 인증을 우회할 수 있다.
2. 서버가 인증의 주체가 된다. (CAN BE)
세션 기반 인증 방식을 예로 들 수 있다. PHP의 경우 PHPSESSIONID=로 시작되는 값은 설정된 어딘가에 sess_ 파일로 저장된다.
OAuth의 경우 DB 등의 data source에 저장한다.
실제 정보는 서버가 소유하고, 사용자는 그 정보에 접근할 수 있는 랜덤 키만을 갖도록 하는 형태이다.
랜덤 키를 예측할 수 없기 때문에 인증 과정을 우회할 수 없다.
다만, 사용자 인증 작업 발생 시마다 IO bound job이 발생한다는 점과, 여러 application에서 세션 정보를 공유할 때에 병목 지점이 된다는 문제가 발생할 수 있는 반면 (stateful이 그 단점의 중심이라 할 수 있겠다.) 그 덕에 노출된 랜덤 키에 대해서는 서버 측에서 언제든 expire 시킬 수 있다는 점이 있다.
3. 서명을 동반한 클라이언트가 인증의 주체가 된다. (CAN BE)
서명을 동반한다는 표현이 애매하나, JWT를 생각하면 된다.
JWT의 경우 인증에 쓰이는 값 자체는 사용자 측의 데이터를 100% 신뢰한다는 가정에서 진행된다.
다만 사용자의 입력 값은 untrusted input으로 간주하기 때문에 서버 측에서 최초 토큰을 발급할 때에 서명을 함께 담아두는 형태이다. 만약 사용자가 임의로 값을 변경했다면, 서명을 통한 verifying에서 오류가 발생한다.
data source에서 인증에 관련된 어떠한 값을 갖고 있을 필요가 없기 때문에 (stateless) 세션 방식과는 반대로 CPU bound job이 발생한다. 문제는 토큰이 유출되었을 경우인데, 인증 정보를 서버 측에서 갖지 않기 때문에 토큰을 expire 할 방법이 없다.
따라서 일반적으로 인증 자체의 임무를 수행하는 access token과 access token을 갱신하는데 이용되는 refresh token 두 개를 발급한다. access token의 경우 expiration due time을 함께 갖고 있는데 이 시간을 일반적으로 짧은 시간으로 설정된다. (15분, 30분 정도) 그리고 access token의 유효기간이 다 되면 refresh token을 통해 access token을 갱신하는데, refresh token의 경우 유효기간은 상당히 긴 편이고(1달 ~ 1년) refresh token의 인증 정보는 서버 측에서 소유하기 때문에 (이 때문에 stateless는 아니지만 15분에 한 번씩 IO bound job이 발생하는 것은 세션 방식에 비해 진보된 방식이라고 볼 수 있다.) refresh token이 유출된 경우엔 서버가 직접 expire 할 수 있다.
그리고 서명에 있어서도 다양한 알고리즘이 지원되는데, Symmetric, Asymmetric 암호화 로직을 제공한다.
대칭키의 경우, 일반적인 해싱 알고리즘으로 서명을 생성하고 같은 키로 서명을 검증하는 형태.
비대칭키의 경우 RSA, ECDSA 등의 알고리즘에서 개인키로 암호화하고 공개키로 검증하는 형태이다.
JWT를 예로 들자면 일반적으로 서비스 벤더의 경우 JWKS(Json Web Key Store)를 사용하여 공개키를 누구든 획득할 수 있도록 하여 검증은 누구나 진행할 수 있도록 한다. (Apple이 그 예)
여기서도 기술적인 이슈가 발생하게 되는데, 세션 방식의 인증을 주로 다루던 엔지니어가 서명 기반의 인증 방식을 도입했을 때의 문제이다. 세션의 경우 서버가 데이터를 갖고 있기 때문에 그 안에 민감한 정보들을 함께 넣어두는 경우가 꽤 많은 편이다.
예를 들자면 privilege라던지, 심한 경우 타 서비스의 토큰 혹은 패스워드인데, 서버가 탈취당하지 않는다면 사실 패스워드를 넣는지 뭐를 넣는지 어차피 사용자는 알 수 없다. 알 필요도 없고.
이러한 형태로 JWT를 처음 접하게 되면 JWT안에 민감 정보를 넣게 되는 경우가 있는데, JWT는 Dot-separated Base64 string list이다. 이게 무슨 소리냐면 (JWT에서 헤더와 서명을 제외한 사용자의 인증에 사용되는 데이터들을 Claim이라 부른다.)
Base64(알고리즘 종류). Base64(Claim). Base64(서명)
형태로 JWT가 구성된다는 의미이고 Base64는 8비트를 스트림을 6비트 단위로 해석하도록 한 것이니 당연히 평문을 볼 수 있는데, 서명 때문에 데이터 위조는 못하더라도 정보 열람은 얼마든 할 수 있다는 것이다.
또, 이러한 사실을 안다고 해도, 서명에 대한 이해가 없는 경우. 예컨대 대칭키 인증 방식에서 secret key를 설정하지 않는다면 데이터를 공격자가 직접 변조할 수 있게 되는데 이 상황에선 사실상 1번의 인증 방식과 다르지 않다.
다음으로 secret key가 너무 짧은 경우이다. 해시 알고리즘과 맥락을 함께하는데, 이 Secret Key가 너무 짧은 경우, 토큰으로부터 secret key brute forcing이 가능하다. 8글자 미만으로 설정된 경우. JWT검증 6.6e+15 (95의 8승) 번으로 secret key를 획득할 수 있게 된다. secret key의 경우 노출되었을 때 모든 인증이 우회 가능해지므로 이 점에 유의할 필요가 있다.
또 다른 케이스로는 JWT 인증 흐름이 생소해서 꽤나 많이 발생하는데, access token의 expire due time을 무기한으로 설정하는 경우이다. access token의 경우 유출되었을 때 해당 토큰에 대한 접근을 제어할 방법이 없기 때문에 (당연한 거지만 방화벽처럼 토큰을 막는 걸 제외하고) 당장에는 문제가 없고 구현이 간단할지 모르지만 사용자의 토큰이 유출된 경우 제어권을 잃게 된다.

그래서 사실 보안적으로 볼 때에는 서버가 주도하는 세션 형태의 인증이 가장 안전하다고 볼 수 있는데 JWT가 뜨고 많이 사용되는 이유는 개발상에서 성능의 이유, 그리고 그에 맞는 용도가 있기 때문이다. (실제로 개발 용이성은 세션 형태가 더 우수하다.)
(예컨대 애플에서 JWT를 사용하는 이유는 Login with apple 기능을 사용하는데 서버 측에서 잠시 유지될 인증 정보에 대한 상태를 굳이 갖고 있을 이유가 없기 때문인 것이라 생각한다.)
물론 정책적인 부분이나 법적인 제재로 개인정보에 대한 인식도 많이 변화했고 기술적인 발전으로 보다 안전한 사용자 정보 저장, 인증이 발달하였으나 모든 일이 그렇듯 정확한 이해가 없는 섣부른 적용은 더욱 위험할 수 있다.
더욱 활발한 지원과 연구를 통해 무지로 인해 발생할 수 있는 맹점을 커버할 수 있게 되면 좋을 것 같다.